Introduction
In this simulation exercise, we use Causal Forest (Now is implemented in Generalized Random Forest) (https://github.com/swager/grf) to calculated conditional average treatment effect (or heterogenous treatment effect). We assume three different data generating processes. The first one is a linear interaction between a variable of interest and the treatment dummy. The second one assumes a nonlinear function (a step function) of a variable of interest, say \(X\), and the treatment dummy \(W\). The third one is also nonlinear, assuming we have variable \(X\), but the real DGP is the interaction of log of \(X\) and \(W\).
Linear effect
Suppose we have a panel of firms over time, treatment assignment is random. We split the data into training and test. Then we generate 10 random variables, the first two are highly correlated. Then we collapse V2 into firm means, and use that as the unit effect. That is, we have a DGP as:
\[y_{it} = \alpha_i + V1_{it} + W_{it} + V1_{it}*W_{it} + \epsilon_{it} \]
Here \(\alpha_i\) is not observed, and it is correlated with \(V1\). If we don’t control for it, we are going to have a biaed estimator.
We run a fixed effect model, and a random effect model and an OLS model. We expect fixed effect model will do well, but not the other two. This is because the other two models do not control for \(\alpha_i\) directly.
# This is a simulation exercise to see how causal forest performs
# First we run a linear model, with panel setting
# Then two nonlinear situations, with panel setting.
library(lfe, quietly = TRUE)
library(lme4)
require(snowfall)
library(MASS)
library(grf)
library(tidyverse)
set.seed(666)
rm(list = ls())
# t is no. of periods. p is no. of variables, n is no. of firms.
t <- 10
p <- 10
n=400
# generate p random variables
data1 = as.data.frame(matrix(rnorm(n*t*p), n*t, p))
firm=seq(1,n)
time=seq(1,t)
data <- expand.grid(firm=firm,time=time)
# W is the treatment assignment
data$W <- rbinom(n*t, 1, 0.5)
data$train <- rbinom(n*t, 1, 0.5)
# generate two correlated variables
covarMat = matrix( c(1, .95^2, .95^2, 1 ) , nrow=2 , ncol=2 )
data.2 = as.data.frame(mvrnorm(n=n*t , mu=rep(0,2), Sigma=covarMat ))
data <- bind_cols(data,data.2) %>%
tbl_df()
data <- bind_cols(data,data1)
# generate unit effect by firm means of V2, which is correlated with V1
data <- data %>%
group_by(firm) %>%
mutate(unit.effect=mean(V2)) %>%
ungroup() %>%
arrange(firm, time)
y<-c()
unit<-c()
X<-c()
k <- 0
for(i in 1:n){
for(j in 1:t){
k<-k+1
unit[k]<-i
y[k]<-1+ data$V1[k] + data$W[k] + data$V1[k]*data$W[k] + data$unit.effect[k]+rnorm(1,mean=0,sd=1)
}
}
data$unit=unit
data$y=y
data.train <- data %>%
filter(train==1)
data.test <- data %>%
filter(train==0)
# run fixed effect, random effect, and ols to see whether they are
# biased.
# in general we should expect fe performs better, since we are
# omitting unit.effect in the other two models
fe <- felm(y ~ V1 * W | unit, data=data.train)
re <-lmer(y~V1*W+(1 | unit), data=data.train)
ols <- lm(y ~ V1 * W , data=data.train)
summary(fe)##
## Call:
## felm(formula = y ~ V1 * W | unit, data = data.train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.0440 -0.6252 -0.0083 0.6221 3.6174
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## V1 0.98354 0.03748 26.24 <2e-16 ***
## W 1.02186 0.05093 20.06 <2e-16 ***
## V1:W 1.04302 0.05237 19.92 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.018 on 1612 degrees of freedom
## Multiple R-squared(full model): 0.7952 Adjusted R-squared: 0.7443
## Multiple R-squared(proj model): 0.7269 Adjusted R-squared: 0.659
## F-statistic(full model):15.61 on 401 and 1612 DF, p-value: < 2.2e-16
## F-statistic(proj model): 1430 on 3 and 1612 DF, p-value: < 2.2e-16summary(re)## Linear mixed model fit by REML ['lmerMod']
## Formula: y ~ V1 * W + (1 | unit)
## Data: data.train
##
## REML criterion at convergence: 5938.9
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.4332 -0.6615 -0.0049 0.6640 3.8329
##
## Random effects:
## Groups Name Variance Std.Dev.
## unit (Intercept) 0.07166 0.2677
## Residual 1.04602 1.0228
## Number of obs: 2014, groups: unit, 399
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 1.00010 0.03539 28.26
## V1 1.02961 0.03486 29.53
## W 1.00333 0.04684 21.42
## V1:W 1.05963 0.04814 22.01
##
## Correlation of Fixed Effects:
## (Intr) V1 W
## V1 0.013
## W -0.656 -0.008
## V1:W -0.007 -0.727 0.025summary(ols)##
## Call:
## lm(formula = y ~ V1 * W, data = data.train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.8384 -0.7101 0.0081 0.7334 4.0053
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.00363 0.03319 30.24 <2e-16 ***
## V1 1.04612 0.03516 29.75 <2e-16 ***
## W 0.99657 0.04712 21.15 <2e-16 ***
## V1:W 1.06458 0.04840 22.00 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.057 on 2010 degrees of freedom
## Multiple R-squared: 0.7249, Adjusted R-squared: 0.7245
## F-statistic: 1765 on 3 and 2010 DF, p-value: < 2.2e-16Now we run Causal Forest on this data. We include all other variables in the data set (but not \(V2\), which is used to generate \(\alpha_i\)), and all the firm dummies, since presumably this will take care of the panel structure (\(\alpha_i\)).
# a is a data set of firm dummies
a <- as.data.frame(model.matrix(y~as.factor(firm),data.train))
X <- as.matrix(bind_cols(data.train[,c(5,7:16)],a))
Y <- data.train$y
W <- data.train$W
# causal forest is run on y against V1, to V10 and firm dummies
tau.forest = causal_forest(X, Y, W)
estimate_average_effect(tau.forest, target.sample = "all")## estimate std.err
## 0.95833787 0.04776685estimate_average_effect(tau.forest, target.sample = "treated")## estimate std.err
## 0.94026731 0.04799509#tau.forest = causal_forest(X, Y, W, num.trees = 4000)
a <- as.data.frame(model.matrix(y~as.factor(firm),data.test))
X.test <- as.matrix(bind_cols(data.test[,c(5,7:16)],a))
Y.test <- data.test$y
W.test <- data.test$W
tau.hat = predict(tau.forest, X.test, estimate.variance = TRUE)
sigma.hat = sqrt(tau.hat$variance.estimates)
data.test$pred <- tau.hat$predictions
ggplot(data.test, aes(x=V1, y=pred)) + geom_point() + geom_abline(intercept = 1, slope = 1)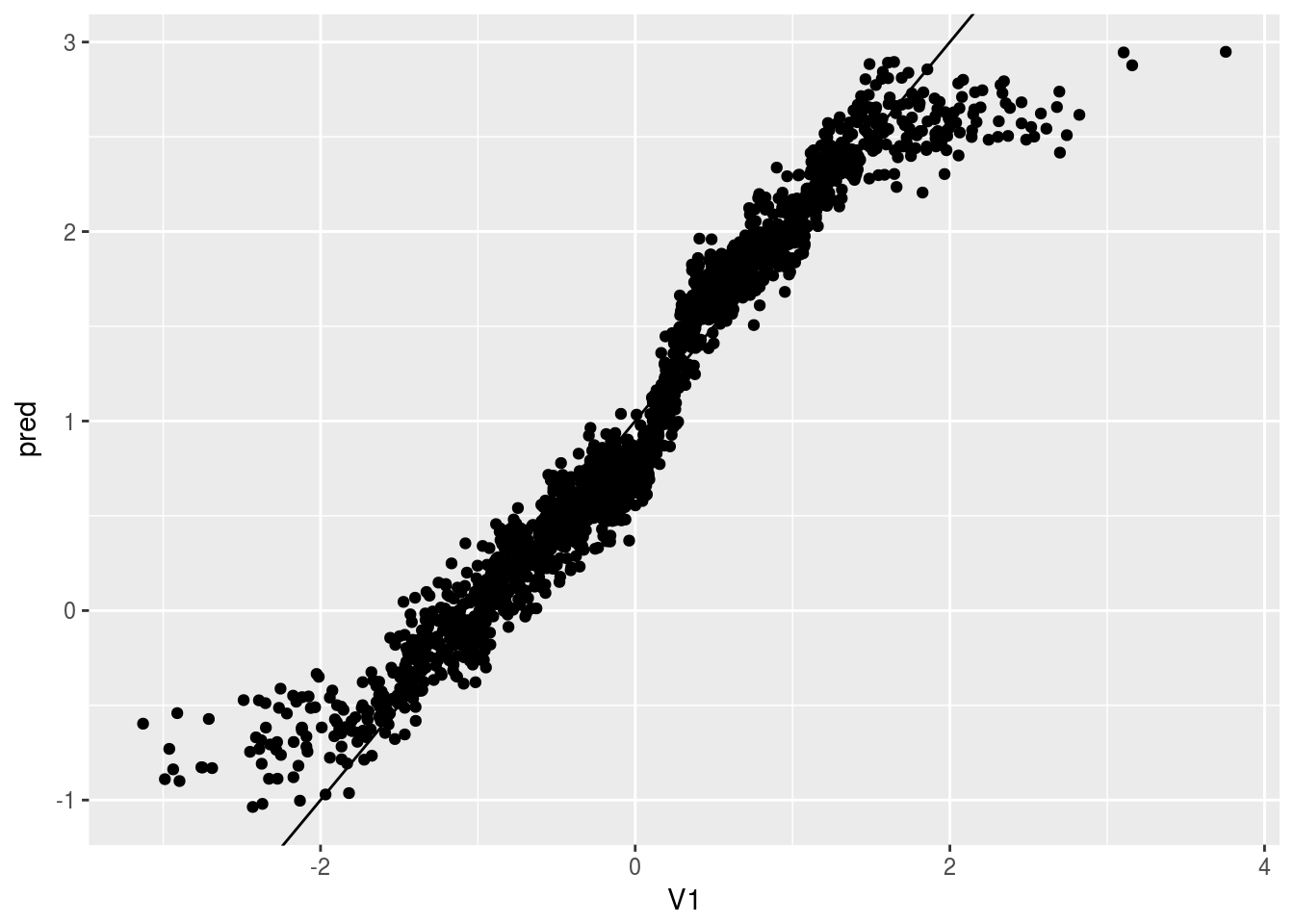
This graph is the predicted value of CATE on the test data, vs. the value of \(V1\).
Now we graph the predicted CATE against the true CATE. The other nice feature of Causal Forest is that it returns variance for CATE for each observation. We also graph the error bar here.
graph.data <- as.data.frame(tau.hat )
graph.data <- graph.data %>%
mutate(cate=1+data.test$V1,0) %>%
mutate(lower=predictions - sigma.hat , upper=predictions + sigma.hat )
ggplot(graph.data , aes(x=cate, y=predictions)) + geom_point() + geom_abline(slope = 1)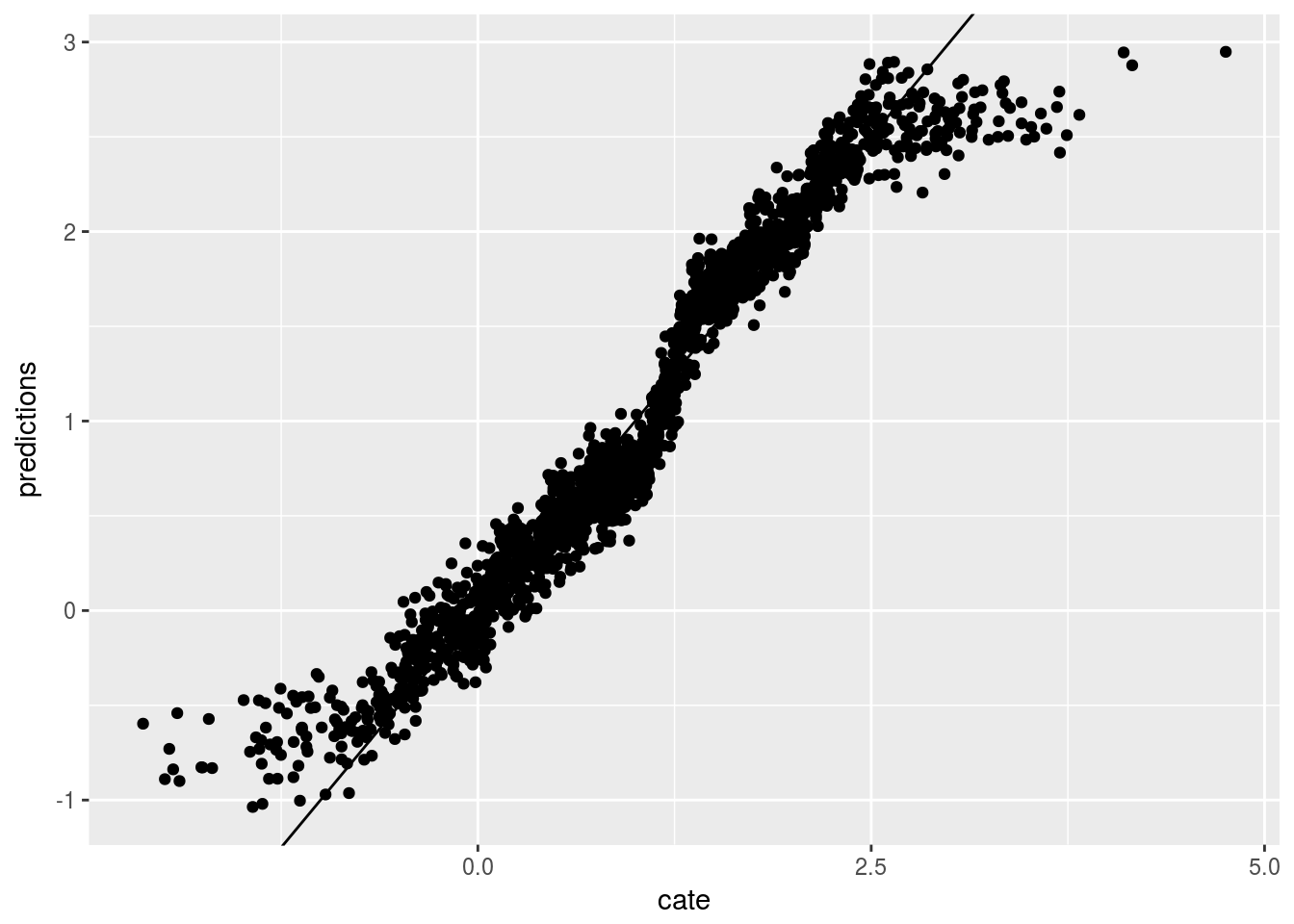
ggplot() + geom_errorbar(graph.data , mapping=aes(x=cate, ymin=lower,ymax=upper), alpha = 0.2) + geom_point(graph.data , mapping=aes(x=cate, y=predictions), alpha = 0.2) + geom_abline(slope = 1)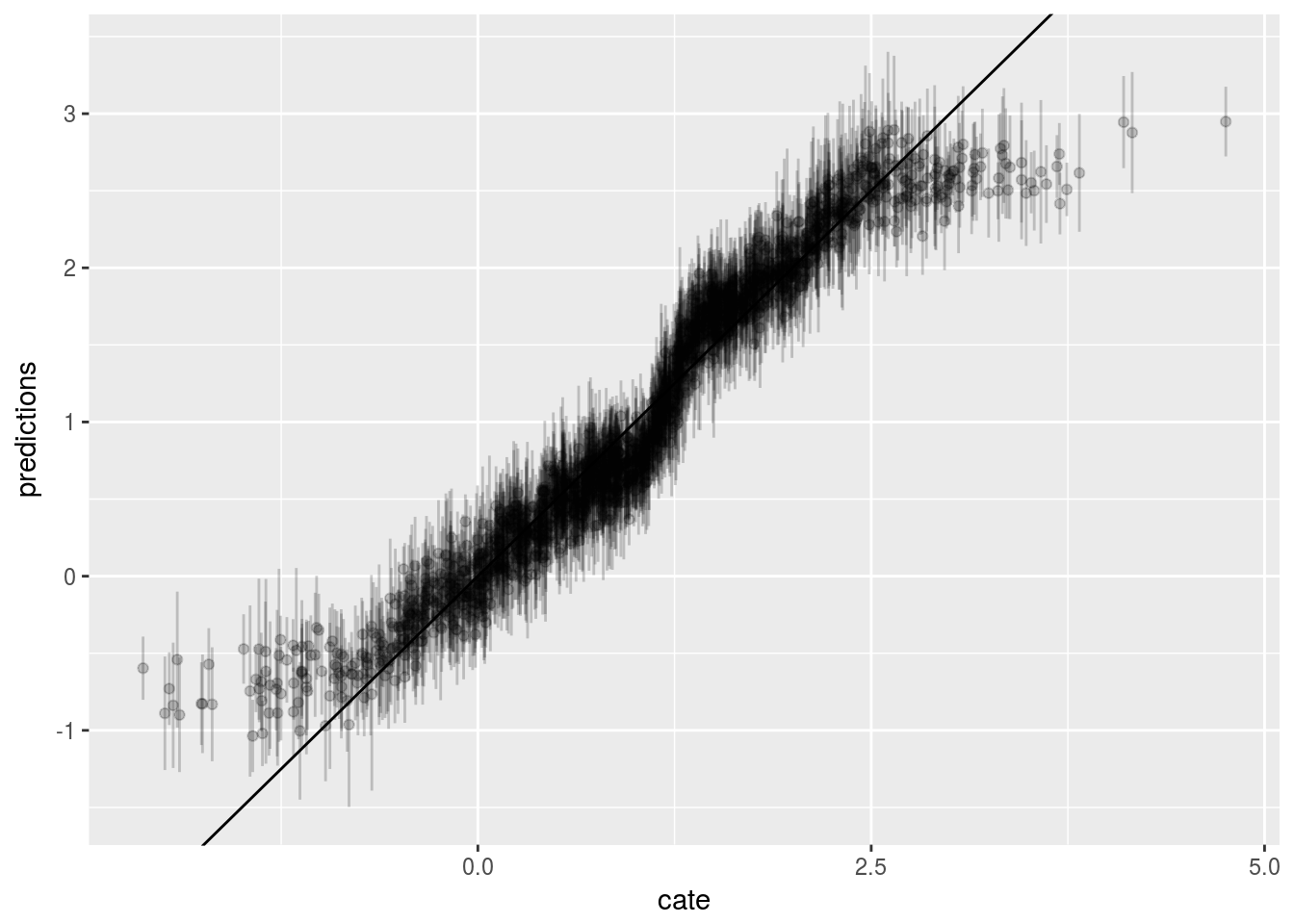
Nonlinear effect case 1
In the first situation, we assume DGP:
\[y_{it} = 1 + \alpha_i + max(V1_{it},0)*W_{it} + \epsilon_{it} \]
# if we have a nonlinear effect
# suppose we have the same X, but y is generated nonlinearly.
# in this example, y is a nonlinear function of V1 and W
set.seed(666)
rm(list = ls())
# t is no. of periods. p is no. of variables, n is no. of firms.
t <- 10
p <- 10
n=400
# generate p random variables
data1 = as.data.frame(matrix(rnorm(n*t*p), n*t, p))
firm=seq(1,n)
time=seq(1,t)
data <- expand.grid(firm=firm,time=time)
# W is the treatment assignment
data$W <- rbinom(n*t, 1, 0.5)
data$train <- rbinom(n*t, 1, 0.5)
# generate two correlated variables
covarMat = matrix( c(1, .95^2, .95^2, 1 ) , nrow=2 , ncol=2 )
data.2 = as.data.frame(mvrnorm(n=n*t , mu=rep(0,2), Sigma=covarMat ))
data <- bind_cols(data,data.2) %>%
tbl_df()
data <- bind_cols(data,data1)
# generate unit effect by firm means of V2, which is correlated with V1
data <- data %>%
group_by(firm) %>%
mutate(unit.effect=mean(V2)) %>%
ungroup() %>%
arrange(firm, time)
y<-c()
unit<-c()
X<-c()
k <- 0
for(i in 1:n){
for(j in 1:t){
k<-k+1
unit[k]<-i
y[k]<-1+ pmax(data$V1[k],0)*data$W[k] + data$unit.effect[i]+rnorm(1,mean=0,sd=1)
}
}
data$y=y
data$unit <- unit
data.train <- data %>%
filter(train==1)
data.test <- data %>%
filter(train==0)
# run fixed effect, random effect, and ols to see whether they are
# biased.
# they all perform poorly
fe <- felm(y ~ V1 * W | unit, data=data.train)
re <-lmer(y~V1*W+(1 | unit), data=data.train)
ols <- lm(y ~ V1 * W , data=data.train)
summary(fe)##
## Call:
## felm(formula = y ~ V1 * W | unit, data = data.train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.9461 -0.6225 -0.0178 0.6245 3.3537
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## V1 -0.02076 0.03815 -0.544 0.586
## W 0.42527 0.05184 8.203 4.73e-16 ***
## V1:W 0.53367 0.05331 10.012 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.036 on 1612 degrees of freedom
## Multiple R-squared(full model): 0.3233 Adjusted R-squared: 0.1549
## Multiple R-squared(proj model): 0.1393 Adjusted R-squared: -0.07481
## F-statistic(full model): 1.92 on 401 and 1612 DF, p-value: < 2.2e-16
## F-statistic(proj model): 86.96 on 3 and 1612 DF, p-value: < 2.2e-16summary(re)## Linear mixed model fit by REML ['lmerMod']
## Formula: y ~ V1 * W + (1 | unit)
## Data: data.train
##
## REML criterion at convergence: 5950.8
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.3755 -0.6722 -0.0069 0.6756 3.3316
##
## Random effects:
## Groups Name Variance Std.Dev.
## unit (Intercept) 0.04251 0.2062
## Residual 1.07611 1.0374
## Number of obs: 2014, groups: unit, 399
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 0.93831 0.03457 27.145
## V1 -0.02588 0.03506 -0.738
## W 0.37531 0.04706 7.975
## V1:W 0.52406 0.04835 10.838
##
## Correlation of Fixed Effects:
## (Intr) V1 W
## V1 0.014
## W -0.675 -0.009
## V1:W -0.009 -0.727 0.027summary(ols)##
## Call:
## lm(formula = y ~ V1 * W, data = data.train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.6531 -0.7271 -0.0072 0.7270 3.4720
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.94431 0.03322 28.429 < 2e-16 ***
## V1 -0.02610 0.03519 -0.741 0.458
## W 0.36555 0.04716 7.752 1.43e-14 ***
## V1:W 0.52286 0.04844 10.794 < 2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.058 on 2010 degrees of freedom
## Multiple R-squared: 0.1209, Adjusted R-squared: 0.1196
## F-statistic: 92.16 on 3 and 2010 DF, p-value: < 2.2e-16Apparently none of these model will return anything meaningful.
Now we use Causal Forest. The first graph is the predicted CATE against \(V1\); the second graph is the predicted CATE against true CATE. The third one adds in error bars.
# a is a data set of firm dummies
a <- as.data.frame(model.matrix(y~as.factor(firm),data.train))
X <- as.matrix(bind_cols(data.train[,c(5,7:16)],a))
Y <- data.train$y
W <- data.train$W
#tau.forest = causal_forest(X, Y, W, num.trees = 4000)
a <- as.data.frame(model.matrix(y~as.factor(firm),data.test))
X.test <- as.matrix(bind_cols(data.test[,c(5,7:16)],a))
Y.test <- data.test$y
W.test <- data.test$W
tau.forest3 = causal_forest(X, Y, W)
estimate_average_effect(tau.forest3, target.sample = "all")## estimate std.err
## 0.33321181 0.04640297estimate_average_effect(tau.forest3, target.sample = "treated")## estimate std.err
## 0.3338136 0.0465098#tau.forest3 = causal_forest(X, Y, W, num.trees = 4000)
tau.hat3 = predict(tau.forest3, X.test, estimate.variance = TRUE)
sigma.hat3 = sqrt(tau.hat3$variance.estimates)
data.test$pred3 <- tau.hat3$predictions
seg1 <- data.frame(x1 = -3, x2 = 0, y1 = 0, y2 = 0)
seg2 <- data.frame(x1 = 0, x2 = 2, y1 = 0, y2 = 2)
ggplot(data.test, aes(x=V1, y=pred3)) + geom_point() +
geom_segment(aes(x = x1, y = y1, xend = x2, yend = y2, colour = "segment"), data = seg1)+
geom_segment(aes(x = x1, y = y1, xend = x2, yend = y2, colour = "segment"), data = seg2)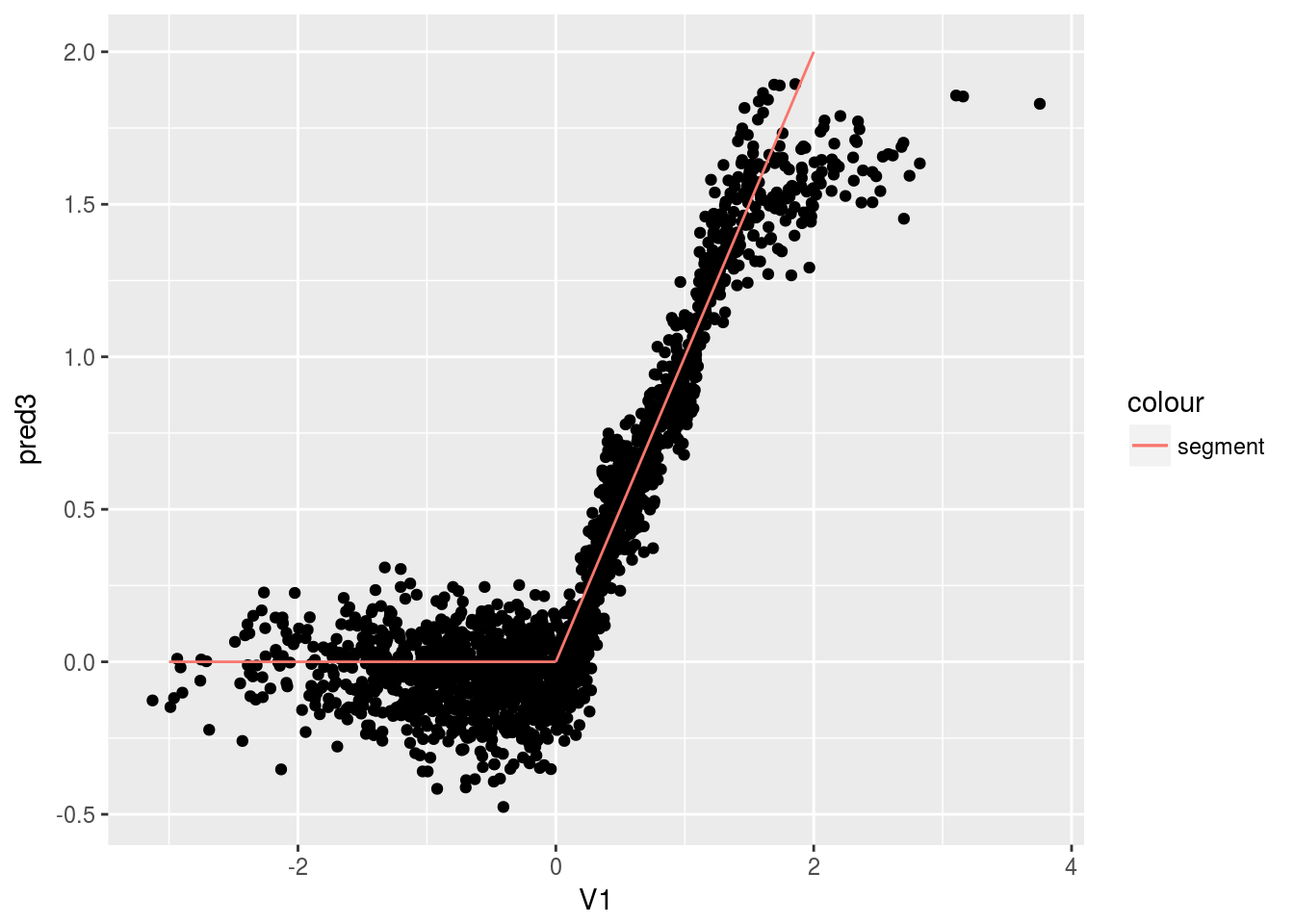
graph.data3 <- as.data.frame(tau.hat3)
graph.data3 <- graph.data3 %>%
mutate(cate=pmax(data.test$V1,0)) %>%
mutate(lower=predictions - sigma.hat3, upper=predictions + sigma.hat3)
ggplot(graph.data3, aes(x=cate, y=predictions)) + geom_point() + geom_abline(slope = 1)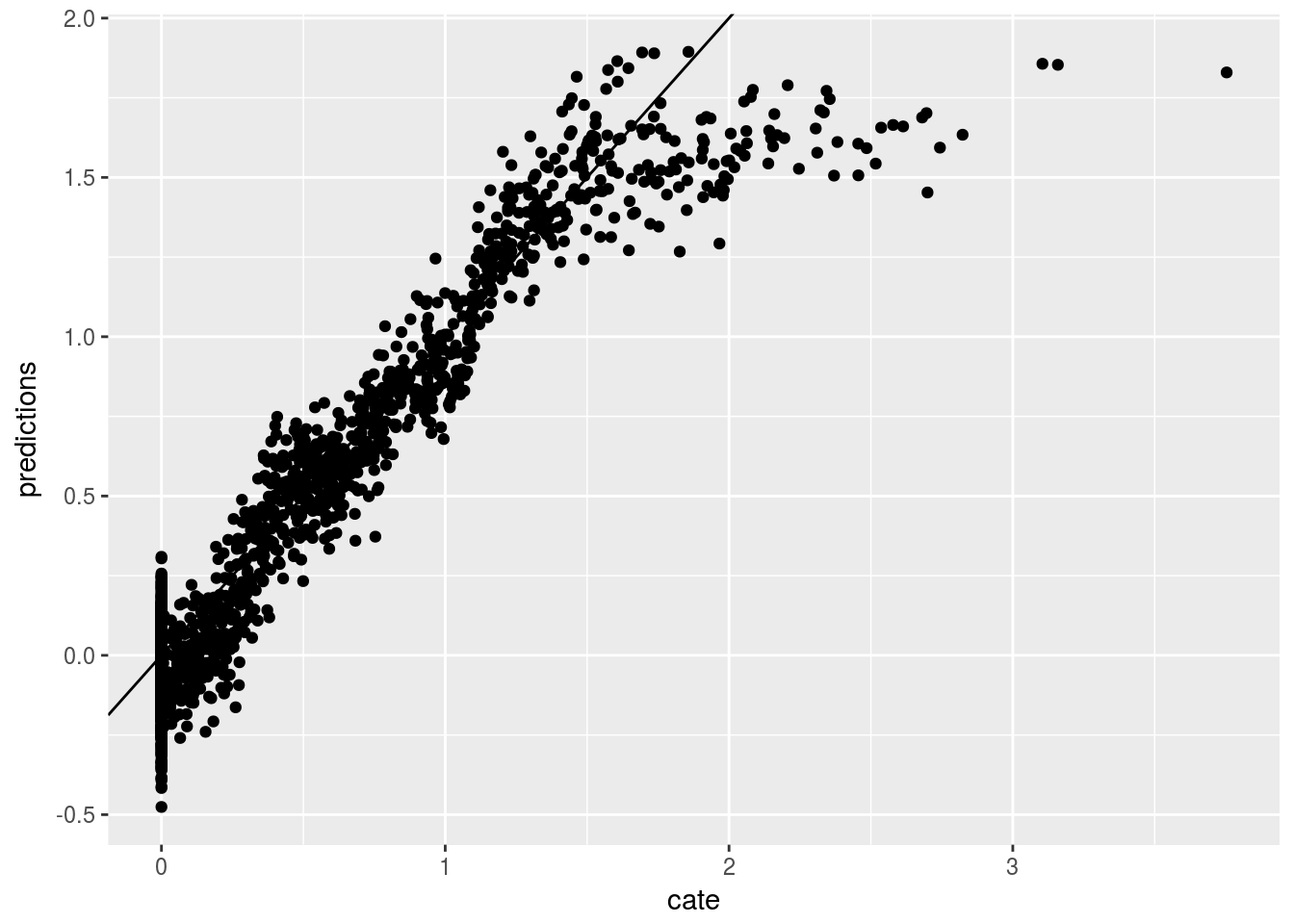
ggplot() + geom_errorbar(graph.data3, mapping=aes(x=cate, ymin=lower,ymax=upper), alpha = 0.2) + geom_point(graph.data3, mapping=aes(x=cate, y=predictions), alpha = 0.2) + geom_abline(slope = 1)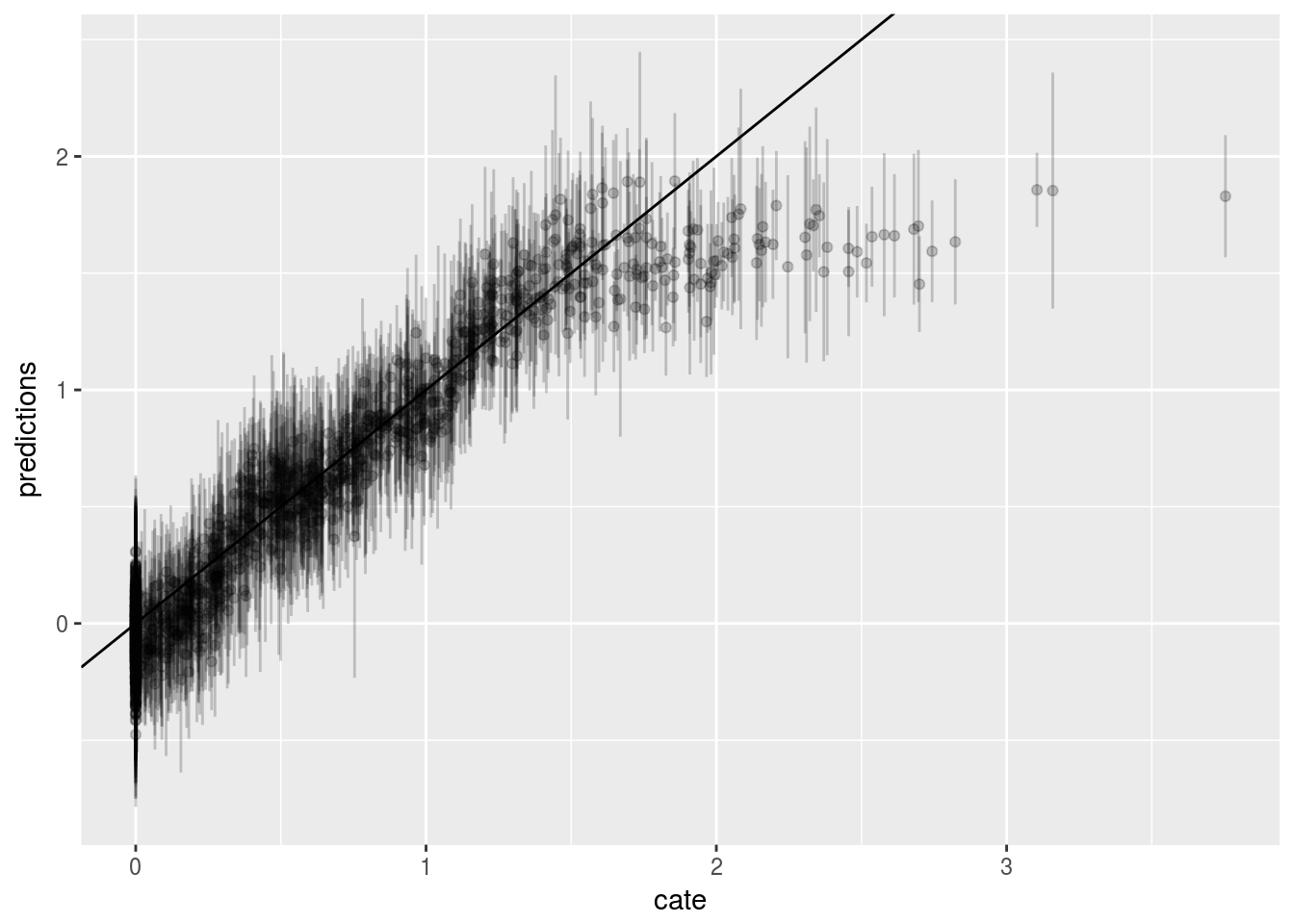
Nonlinear effect case 2
In the second situation, we assume DGP:
\[y_{it} = 1 + \alpha_i + log(V1_{it}^2)*W_{it} + \epsilon_{it} \]
But we only observe \(V1\), not the log of the squared \(V1\).
# if we have a nonlinear effect
# suppose we have the same X, but y is generated nonlinearly.
# another example, suppose we observe log(V1), but the true effect is V1
set.seed(666)
rm(list = ls())
# t is no. of periods. p is no. of variables, n is no. of firms.
t <- 10
p <- 10
n=400
# generate p random variables
data1 = as.data.frame(matrix(rnorm(n*t*p), n*t, p))
firm=seq(1,n)
time=seq(1,t)
data <- expand.grid(firm=firm,time=time)
# W is the treatment assignment
data$W <- rbinom(n*t, 1, 0.5)
data$train <- rbinom(n*t, 1, 0.5)
# generate two correlated variables
covarMat = matrix( c(1, .95^2, .95^2, 1 ) , nrow=2 , ncol=2 )
data.2 = as.data.frame(mvrnorm(n=n*t , mu=rep(0,2), Sigma=covarMat ))
data <- bind_cols(data,data.2) %>%
tbl_df()
data <- bind_cols(data,data1)
# generate unit effect by firm means of V2, which is correlated with V1
data <- data %>%
group_by(firm) %>%
mutate(unit.effect=mean(V2)) %>%
ungroup() %>%
arrange(firm, time)
y<-c()
unit<-c()
X<-c()
k <- 0
for(i in 1:n){
for(j in 1:t){
k<-k+1
unit[k]<-i
y[k]<-1+ log(data$V1[k]^2)*data$W[k] + pmin(data$V3, 0) + data$unit.effect[i]+rnorm(1,mean=0,sd=1)
}
}
data$y=y
data$unit <- unit
data.train <- data %>%
filter(train==1)
data.test <- data %>%
filter(train==0)
# run fixed effect, random effect, and ols to see whether they are
# biased.
# they all perform poorly
fe <- felm(y ~ V1 * W | unit, data=data.train)
re <-lmer(y~V1*W+(1 | unit), data=data.train)
ols <- lm(y ~ V1 * W , data=data.train)
summary(fe)##
## Call:
## felm(formula = y ~ V1 * W | unit, data = data.train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -10.4938 -0.8785 0.0891 0.9992 5.2491
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## V1 -0.04144 0.06812 -0.608 0.543
## W -1.23652 0.09257 -13.358 <2e-16 ***
## V1:W 0.01293 0.09518 0.136 0.892
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.85 on 1612 degrees of freedom
## Multiple R-squared(full model): 0.2947 Adjusted R-squared: 0.1193
## Multiple R-squared(proj model): 0.09981 Adjusted R-squared: -0.1241
## F-statistic(full model): 1.68 on 401 and 1612 DF, p-value: 2.282e-12
## F-statistic(proj model): 59.58 on 3 and 1612 DF, p-value: < 2.2e-16summary(re)## Linear mixed model fit by REML ['lmerMod']
## Formula: y ~ V1 * W + (1 | unit)
## Data: data.train
##
## REML criterion at convergence: 8240.8
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -6.2590 -0.4652 0.0663 0.5790 2.6978
##
## Random effects:
## Groups Name Variance Std.Dev.
## unit (Intercept) 0.05461 0.2337
## Residual 3.43184 1.8525
## Number of obs: 2014, groups: unit, 399
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) -0.45725 0.05967 -7.664
## V1 -0.02699 0.06208 -0.435
## W -1.26979 0.08324 -15.254
## V1:W -0.03438 0.08552 -0.402
##
## Correlation of Fixed Effects:
## (Intr) V1 W
## V1 0.015
## W -0.692 -0.010
## V1:W -0.010 -0.727 0.028summary(ols)##
## Call:
## lm(formula = y ~ V1 * W, data = data.train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -11.7006 -0.8590 0.1257 1.0919 5.0430
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -0.45475 0.05864 -7.754 1.4e-14 ***
## V1 -0.02610 0.06214 -0.420 0.675
## W -1.27236 0.08326 -15.282 < 2e-16 ***
## V1:W -0.03617 0.08552 -0.423 0.672
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.867 on 2010 degrees of freedom
## Multiple R-squared: 0.1044, Adjusted R-squared: 0.103
## F-statistic: 78.08 on 3 and 2010 DF, p-value: < 2.2e-16Again, these models do not work.
Now we run Causal Forest. Again, first graph is prediced CATE against \(V1\), the second one is the prediced CATE against true CATE, the third one adds error bars.
# a is a data set of firm dummies
a <- as.data.frame(model.matrix(y~as.factor(firm),data.train))
X <- as.matrix(bind_cols(data.train[,c(5,7:16)],a))
Y <- data.train$y
W <- data.train$W
#tau.forest = causal_forest(X, Y, W, num.trees = 4000)
a <- as.data.frame(model.matrix(y~as.factor(firm),data.test))
X.test <- as.matrix(bind_cols(data.test[,c(5,7:16)],a))
Y.test <- data.test$y
W.test <- data.test$W
tau.forest4 = causal_forest(X, Y, W)
estimate_average_effect(tau.forest4, target.sample = "all")## estimate std.err
## -1.30599778 0.05081702estimate_average_effect(tau.forest4, target.sample = "treated")## estimate std.err
## -1.28822989 0.05102821#tau.forest3 = causal_forest(X, Y, W, num.trees = 4000)
tau.hat4 = predict(tau.forest4, X.test, estimate.variance = TRUE)
sigma.hat4 = sqrt(tau.hat4$variance.estimates)
data.test$pred4 <- tau.hat4$predictions
fun.1 <- function(x) log(x^2)
ggplot(data.test, aes(x=V1, y=pred4)) + geom_point() +
stat_function(fun = fun.1, colour="red") + xlim(-3,3)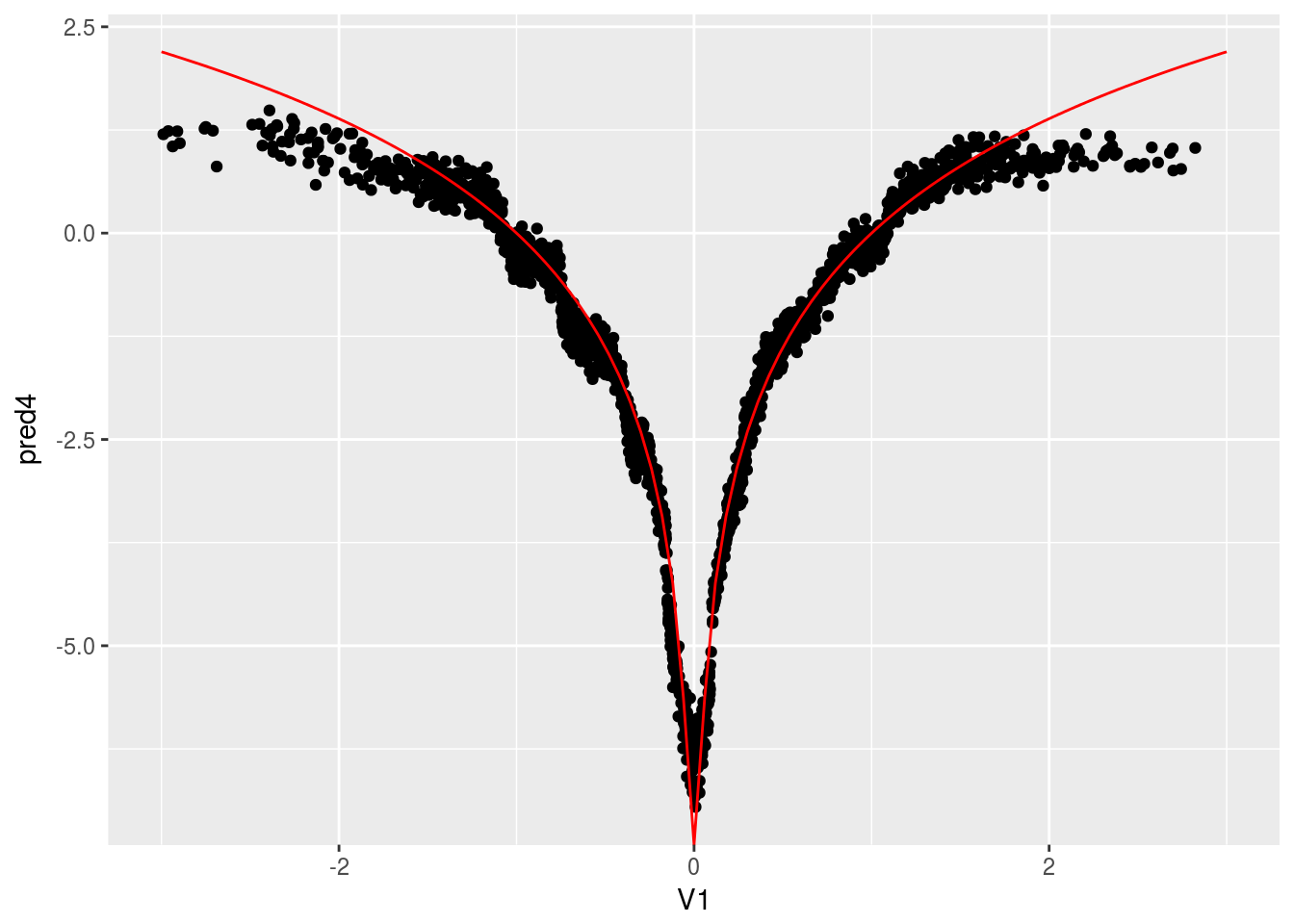
graph.data4 <- as.data.frame(tau.hat4)
graph.data4 <- graph.data4 %>%
mutate(cate=log(data.test$V1^2)) %>%
mutate(lower=predictions - sigma.hat4, upper=predictions + sigma.hat4)
ggplot(graph.data4, aes(x=cate, y=predictions)) + geom_point() + geom_abline(slope = 1)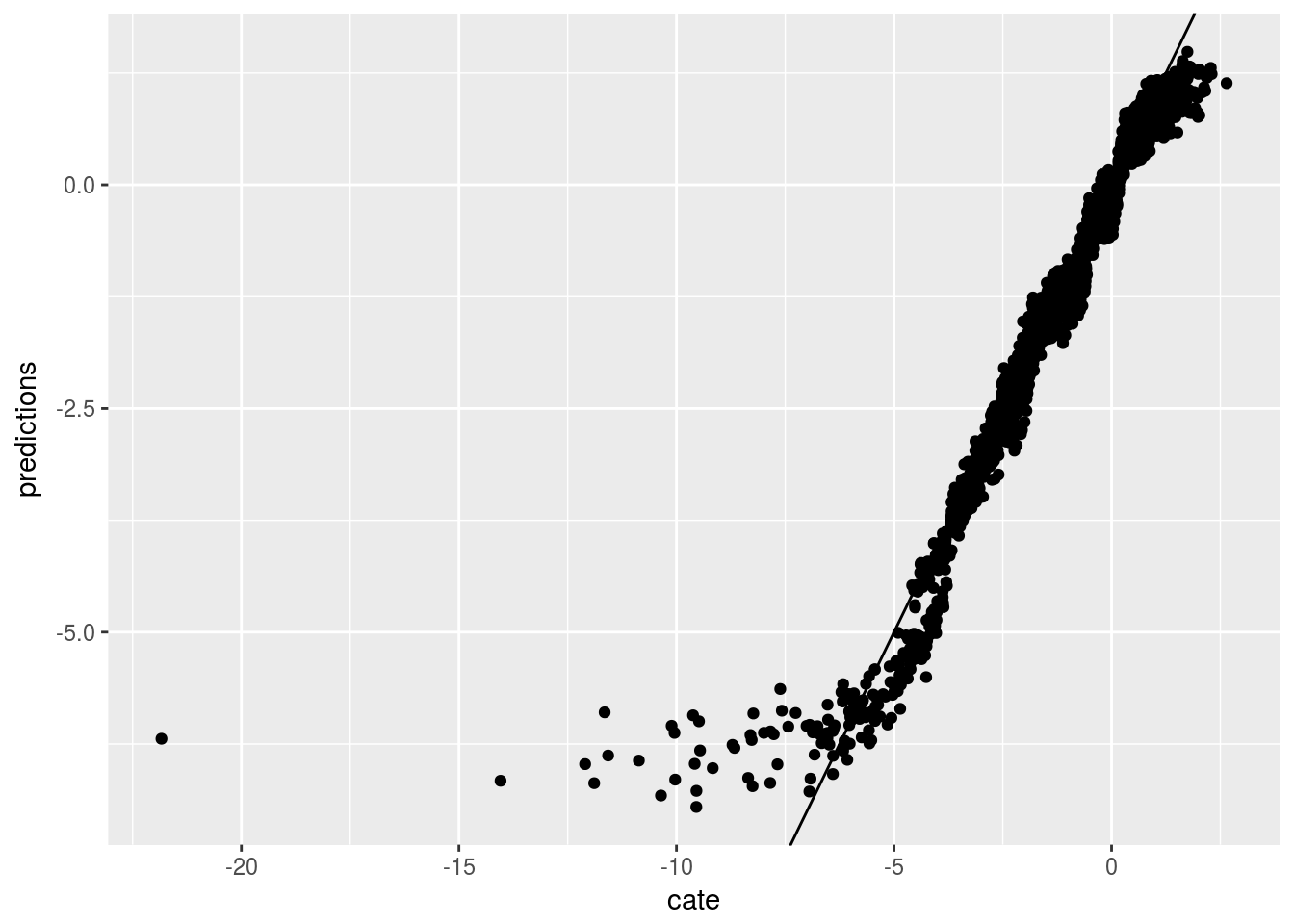
ggplot() + geom_errorbar(graph.data4, mapping=aes(x=cate, ymin=lower,ymax=upper), alpha = 0.2) + geom_point(graph.data4, mapping=aes(x=cate, y=predictions), alpha = 0.2) + geom_abline(slope = 1)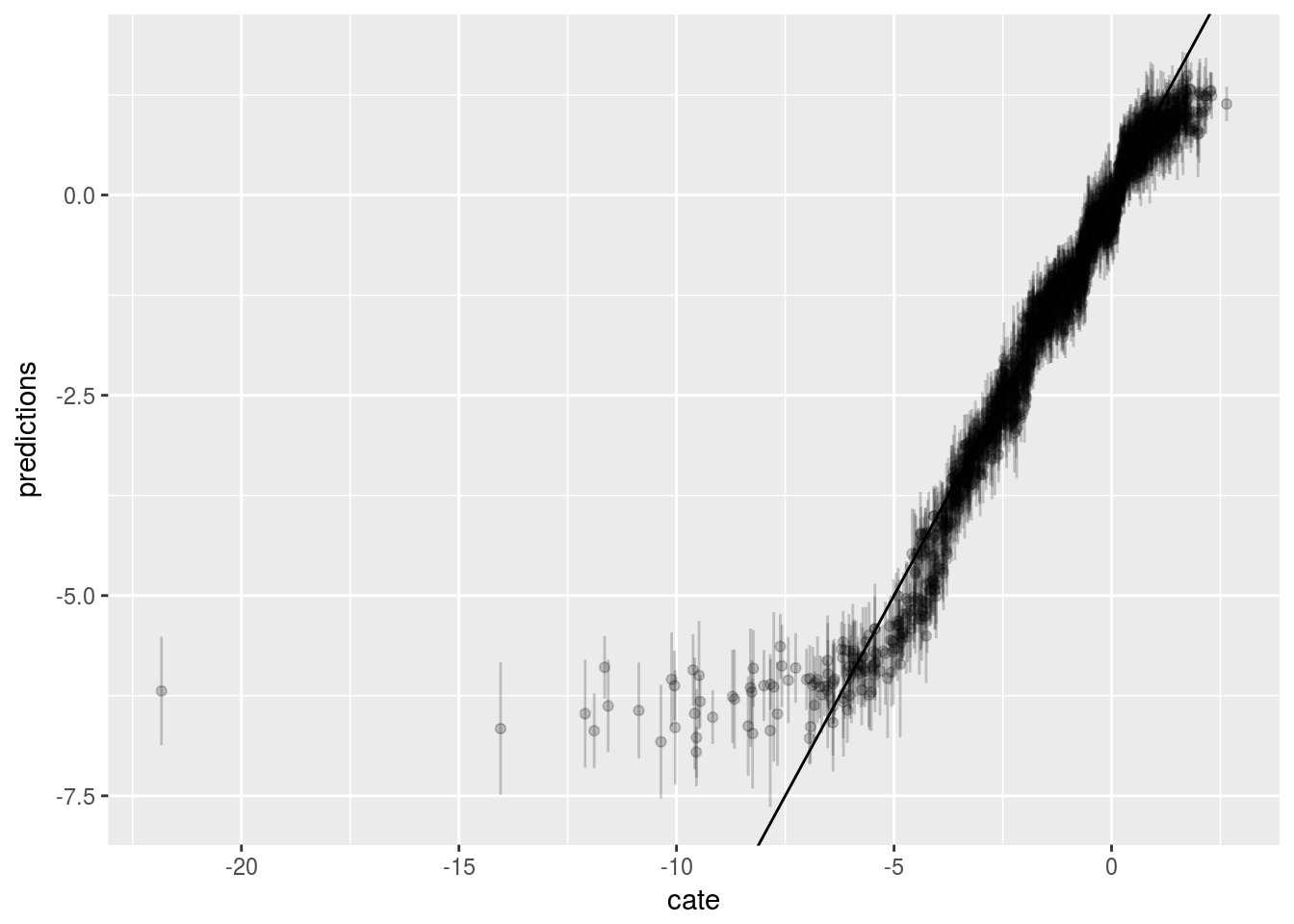
Summary
We see in these examples, Causal Forest performs fairly well, while other linear models will not work in the nonlinear DGP situations.